【続編】BigQueryで「AIに引用されている記事」を特定し、LLMO最適化につなげる
前編では、GoogleスプレッドシートをBigQueryの外部テーブルとして登録し、記事ごとの公開日・リライト日・アンケート反映フラグをGA4やGSCと一緒に扱える状態を作った。
この記事はその続きだ。
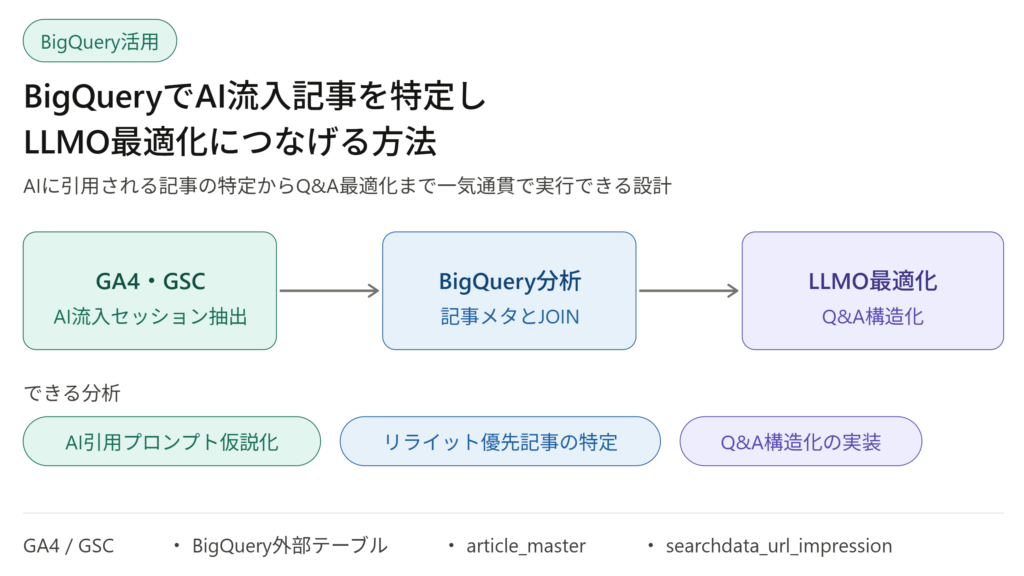
外部テーブルが用意できたことで、「どの記事がAIに引用されているか」「そのページにはどんな検索クエリが集まっているか」という分析が一気通貫でできるようになる。この記事では実際に★様のケースで行った分析と、そこから導いたLLMO最適化の方向性までを共有する。
この記事で分かること
- GA4のBigQueryエクスポートからAI経由流入を抽出するSQL
- AI流入記事と記事マスタをJOINしてリライト回数との関係を見る方法
- AI流入記事のGSCクエリから「AIが引用している検索意図」を仮説化する方法
- 仮説をもとにLLMO最適化(Q&A構造化)を実装する考え方
AI経由流入の定義
GA4上でAI経由流入を定義するにはいくつかの方法があるが、今回は「リファラーにAIツールのドメインが含まれているセッション」を対象にした。具体的には以下のソースを対象にしている。
- chatgpt.com
- perplexity.ai
- gemini.google.com
- copilot.com
GoogleのAIオーバービュー経由はGA4のリファラーに現れないため、今回の分析には含まれない。AIオーバービューの計測は別途GSCのインプレッション変化で追うのが現実的だ。
ステップ1:AI経由のランディングページをGA4から抽出する
GA4のBigQueryエクスポートテーブル(events_*)と、前編で作った外部テーブル(article_master)をJOINして、AI経由で流入のあった記事だけを絞り込む。
WITH ai_sessions AS (
SELECT
REGEXP_EXTRACT(
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'),
r'(https?://[^?#]+)'
) AS normalized_url,
CASE
WHEN LOWER(traffic_source.source) LIKE '%perplexity%' THEN 'perplexity.ai'
WHEN LOWER(traffic_source.source) LIKE '%chatgpt%' THEN 'chatgpt.com'
WHEN LOWER(traffic_source.source) LIKE '%gemini%' THEN 'gemini.google.com'
WHEN LOWER(traffic_source.source) LIKE '%copilot%' THEN 'copilot.com'
END AS source,
COUNT(*) AS sessions
FROM `sample-project.analytics_sample.events_*`
WHERE event_name = 'session_start'
AND _TABLE_SUFFIX BETWEEN '20250101' AND FORMAT_DATE('%Y%m%d', CURRENT_DATE())
AND (
LOWER(traffic_source.source) LIKE '%perplexity%'
OR LOWER(traffic_source.source) LIKE '%chatgpt%'
OR LOWER(traffic_source.source) LIKE '%gemini%'
OR LOWER(traffic_source.source) LIKE '%copilot%'
)
GROUP BY 1, 2
)
SELECT
s.normalized_url,
s.source,
s.sessions,
am.published_at,
am.rewritten_at_1,
am.rewritten_at_2,
am.rewritten_at_3,
am.survey_applied,
(CASE WHEN am.rewritten_at_1 IS NOT NULL THEN 1 ELSE 0 END
+ CASE WHEN am.rewritten_at_2 IS NOT NULL THEN 1 ELSE 0 END
+ CASE WHEN am.rewritten_at_3 IS NOT NULL THEN 1 ELSE 0 END) AS rewrite_count
FROM ai_sessions s
INNER JOIN `sample-project.analytics_sample.article_master` am
ON RTRIM(s.normalized_url, '/') = RTRIM(am.url, '/')
ORDER BY s.sessions DESC;※プロジェクトIDやデータセット名は 「sample-project.analytics_sample」と表記しているので、各IDとデータセット名に入れ替え注意
perplexity と perplexity.ai がGA4上では別ソースとして記録されていることがあるため、CASE式で正規化している。INNER JOIN にすることで、LPやトップページなどarticle_masterに登録していないページは自動的に除外される。
ステップ2:分析結果から読み取ったこと
★様のケースで実際に出てきた結果を、まとめる。
ソース別の傾向
chatgpt.comがAI流入全体の約7割を占めていた。次いでperplexity.ai が約2割、copilot.comはごく少数だった。コンテンツを検索して引用するという行動がChatGPTユーザーに最も多いのは、日本国内のAIツール利用状況と一致している。
リライト回数とAI流入の関係
| リライト回数 | 対象記事数 | 合計セッション |
|---|---|---|
| 0回 | 13記事 | 19セッション |
| 1回 | 9記事 | 16セッション |
| 2回 | 3記事 | 3セッション |
| 3回 | 1記事 | 2セッション |
リライト回数が多い記事ほどAI流入が多い、という相関は見られなかった。リライト未実施の記事でも普通にAIに引用されている。
これは「コンテンツの量や更新頻度よりも、テーマとクエリの一致度がAI引用の決め手になっている」という仮説を支持する結果として一理ある。AIが質問への回答として適切かどうかを優先して引用先を選んでいることがわかる。
ステップ3:AI流入記事のGSCクエリと照合する
AI経由で流入した記事が、GSCでどんな検索クエリを持っているかを確認すると、「AIがどんな質問に答えるときにこの記事を使っているか」を推測できる。
WITH ai_sessions AS (
SELECT DISTINCT
RTRIM(
REGEXP_EXTRACT(
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location'),
r'(https?://[^?#]+)'
), '/'
) AS normalized_url
FROM `sample-project.analytics_sample.events_*`
WHERE event_name = 'session_start'
AND _TABLE_SUFFIX BETWEEN '20250101' AND FORMAT_DATE('%Y%m%d', CURRENT_DATE())
AND (
LOWER(traffic_source.source) LIKE '%perplexity%'
OR LOWER(traffic_source.source) LIKE '%chatgpt%'
OR LOWER(traffic_source.source) LIKE '%gemini%'
OR LOWER(traffic_source.source) LIKE '%copilot%'
)
),
article_urls AS (
SELECT RTRIM(url, '/') AS url
FROM `sample-project.analytics_sample.article_master`
),
ai_urls AS (
SELECT s.normalized_url
FROM ai_sessions s
INNER JOIN article_urls a ON s.normalized_url = a.url
),
gsc AS (
SELECT
RTRIM(url, '/') AS url,
query,
SUM(clicks) AS clicks,
SUM(impressions) AS impressions,
ROUND(AVG(sum_position) + 1, 1) AS avg_position
FROM `sample-project.searchconsole.searchdata_url_impression`
WHERE data_date BETWEEN '2025-01-01' AND CURRENT_DATE()
AND is_anonymized_query = FALSE
GROUP BY 1, 2
)
SELECT
a.normalized_url,
g.query,
g.clicks,
g.impressions,
g.avg_position
FROM ai_urls a
INNER JOIN gsc g ON a.normalized_url = g.url
ORDER BY a.normalized_url, g.clicks DESC;GSCテーブルのカラム名は sum_top_position ではなく sum_position であることに注意。BigQueryコンソールのエラーメッセージに「Did you mean sum_position?」と出てくるので、そこで気づける。
得られたAIプロンプト仮説
★様のケースでは、AI流入のあった記事について以下のようなプロンプト仮説が立てられた。
| 記事テーマ(sample) | AIソース | 想定されるユーザープロンプト |
|---|---|---|
| ○○成分の効果について | perplexity.ai | 「○○成分の効果は?」「○○水とは」 |
| ウォーターサーバーのレンタルについて | chatgpt.com | 「ウォーターサーバーのレンタルとは何か」 |
| 月々のランニングコスト比較 | chatgpt.com | 「ウォーターサーバーの電気代は?」 |
| 1日の推奨摂取量について | chatgpt.com | 「1日に水を何リットル飲むべき?」 |
| ○○の健康効果 | perplexity.ai | 「○○の効果は?毎日飲んでいいの?」 |
共通しているのは、「〜とは」「〜は?」「〜の効果は?」という定義・効果・比較を求める質問形式だ。SEOでいう「Know」クエリがAIに引用されやすいという状態になっている。
クエリごとの性質や掘り下げは、それぞれ異なるので今回の記事では言及しない。
ステップ4:LLMO最適化の実装方針
仮説が立てられたら、次は記事をAIに引用されやすい構造に改修する。
なぜ「Q&A」が有効といわれているのか?
AIが記事を引用するとき、ページ全体を読んで要約するのではなく、質問に対して最も直接的に回答している段落を抜き出して使う。つまり「この記事は○○について書いてある」という全体像ではなく、「この段落には○○という質問への回答がある」というその特定の文節や段落だけを引っ張ってくる「チャンク」とよばれる処理をしているからだ。
Q&A形式で明示的な回答段落を置くと、AIがその部分を引用しやすくなる。
実装例(sample)
リライト前の構造:
H1: ○○成分の効果とは?ウォーターサーバーで飲む方法まで解説
H2: ○○成分って何?
H2: ○○成分の主な効果H2: ○○成分が含まれるウォーターサーバー比較
LLMO最適化検証するための構造:
H1: ○○成分の効果とは?ウォーターサーバーで飲む方法まで解説
【この記事でわかること】
Q. ○○成分とは何ですか?
A. ○○成分(化学名:△△)は〜〜〜。水に含まれる天然のミネラル成分で、〜〜という特徴があります。
Q. ○○成分を毎日飲むとどんな効果がありますか?
A. 継続的に摂取することで〜〜〜という報告があります。ただし〜〜〜には個人差があります。
H2: ○○成分って何?
FAQ構造化データとの組み合わせ
冒頭Q&AにFAQPage構造化データを合わせると、Googleの検索結果にも引用されやすくなる。SEOとLLMO両面で効くのでセットで実装するのが効率的だ。
JSON
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "○○成分とは何ですか?",
"acceptedAnswer": {
"@type": "Answer",
"text": "○○成分(化学名:△△)は〜〜〜。"
}
}
]
}しかし、FAQ構造化データのリッチリザルトはサポートが終了された。
参考:構造化データでよくある質問をマークアップする | Google 検索セントラル
まとめ:データドリブンなLLMO最適化の流れ
この記事でやった一連の流れをまとめると以下になる。
- GA4の events_* テーブルからAIリファラーセッションを抽出する
- 前編で作った article_master とJOINして、AI流入のある記事を特定する
- GSCの searchdata_url_impression と照合し、その記事が持つ検索クエリを把握する
- 上位クエリから「AIが答えているであろうプロンプト」を仮説化する
- 仮説に基づいて冒頭Q&Aを追加し、FAQ構造化データを実装する
感覚ベースで「AIに引用されそうな記事を書く」のではなく、「すでにAIに引用されている記事のパターン」を自社データから読み取り、同じ構造を他の記事に横展開するというアプローチも一理あるのではないだろうか。
BigQueryに記事マスタを連携した目的は、最終的にここにある。GA4・GSC・記事メタ情報が一つのクエリで結合できるようになると、こういった多面的な分析が初めて走るようになる。
分析をやってみて気づいたこと
SQLのエラーで時間を取られやすいポイントを共有しておく。
sum_top_position というカラム名はBigQueryのGSCエクスポートには存在しない。正しくは sum_position だ。エラーメッセージが「Did you mean sum_position?」と親切に教えてくれるので、見落とさないように。
また、BigQueryのIN句に別テーブルへのサブクエリを入れると「Correlated subqueries that reference other tables are not supported」というエラーが出ることがある。この場合はサブクエリをCTEに切り出してJOINに書き直すと解決する。前半のSQLではこの構造になっているので参考にしてほしい。
そして、これらはすべてClaudeにお任せすれば解決してくれる。