AI検索で実体がどう見えているかを診断する手順を整理しておく

AIクローラーのBotの種類や、サーバーログをBigQueryに入れて計測する検証を進めていく中で、ひとつ手前に大事な論点があることに気づいた。Botが来ているかを測る前に、そもそもその実体が今AIにどう認識されているのかを診断する手順が要る、という点だ。ここを検証して整理できたので記録しておく。
ここでいう実体とは、会社・サービス・人物・ブランドなど、AIに認識・引用されたい対象のことだ。自社でもクライアントでもいい。AI検索の文脈で「文字列」ではなく「一つの独立したまとまり」として扱われる単位、と捉えている。
結論から書くと、診断は階層を分けて考えるのが要点だった。
まず手前に、クローラーがそもそもサイトに来てコンテンツを取得できているか、というアクセスの層がある。これは事前学習でもウェブ検索でもなく、物理的に到達できているかという話で、ログを見れば分かる。その上に、実際にAIの回答にその実体が出てくるか、というアウトプットの層がある。こちらはログに出ないので、AIに直接聞かないと分からない。アクセスとアウトプットは別物で、混ぜると診断を見誤る。
そして、アウトプットの層をさらに細かく見るときに、AIの検索機能をオフ/オンで切り替える。検索オフなら事前学習に定着しているか、検索オンならウェブ検索のインデックスで引けるか、が分かる。事前学習とウェブ検索という2系統の話は、ここ(アウトプットの層の中)で出てくる。
クロールされている=引用されている、ではない(まだ仮説)
最初に引っかかったのはここだった。サーバーログをBigQueryに入れれば、AIのクローラーが来て正常応答(200)を返した回数は分かるはずだ。ただ、ここで「これだけクロールされているなら引用もされているだろう」と考えるのは、論理的に飛躍があると思う。
クローラーがコンテンツを取得することと、AIが回答の中でその実体を引用することは、まったく別の段階のはずだ。クロールされていても、AIの回答に一度も出てこない、ということは起こりうる。
だとすると、クロール回数と流入数を見比べて指標を作っても意味がない。ボットの来訪と人間のクリックは単位が違うし、その間に「引用される」という段階が挟まっているからだ。
ただし、この部分はまだ実データで確かめていない。サーバーログをBigQueryに入れる環境がまだなく、クロール回数も引用回数も手元にない。あくまで論理的に整理した仮説の段階だ。実際に計測できるようになったら、クロール数と引用・流入の関係を見て、この仮説を確かめたい。これは後述の「次にやること」に入れた。
診断を2つの層に分けて考える
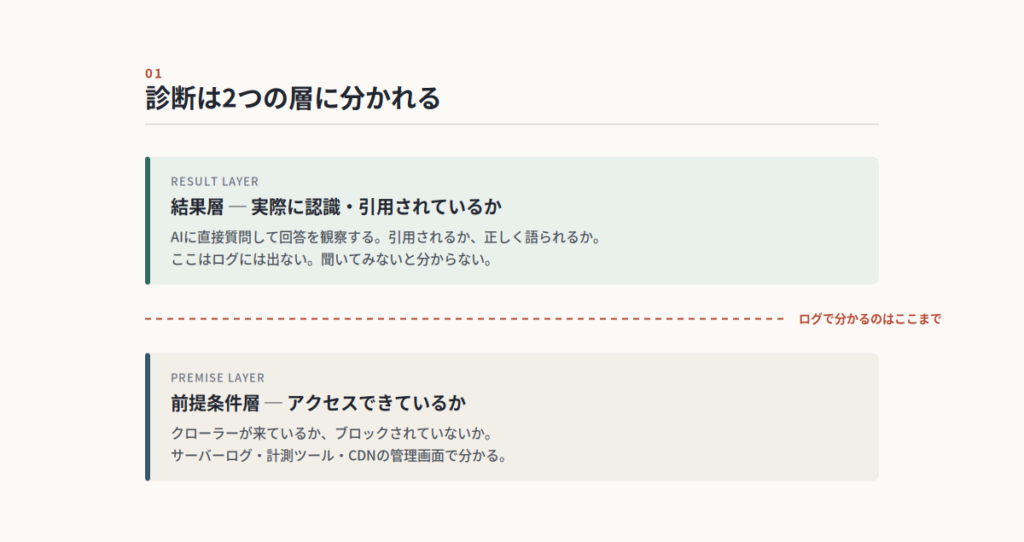
整理すると、診断は2層になる。
前提条件層は、アクセスできているか。クローラーが来ているか、途中でブロックされていないか。これはサーバーログや計測ツール、CDNの管理画面で分かる。
結果層は、実際にAIに認識・引用されているか。これはAIに質問を投げて回答を観察するしかない。
ログで分かるのは前提条件層だけ、というのが要点だった。クローラーは来ているのに回答には出てこない、というギャップこそが本当に見たいものなのに、ログだけ見ていると気づけない。だから結果層を別途診断する必要がある。
検索のオン/オフで学習と検索を切り分ける
結果層を診断するときのコツとして、AIの検索機能をオン/オフで切り替える方法を試した。
検索をオフにすると、AIは学習済みの知識だけで答える。つまり学習データにその実体がどう定着しているかが見える。検索をオンにすると、その場で検索インデックスを見に行って答える。つまり検索インデックスで引き当てられ引用されるかが見える。
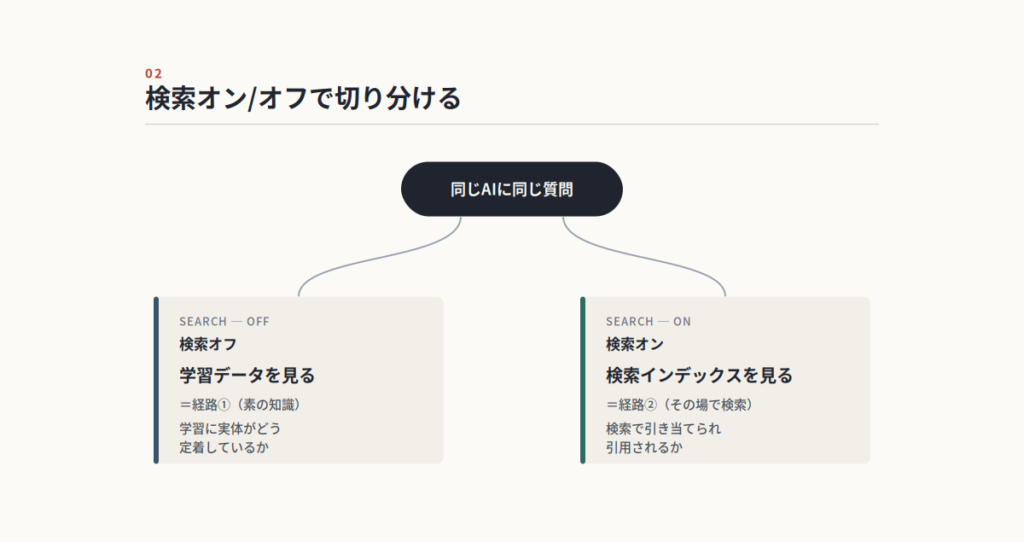
同じAIに同じ質問を、検索オン/オフ両方で投げる。これで、学習と検索のどちらを見ているのかを切り分けられる。普段は「AIに聞いたら出た/出なかった」で終わりがちだが、それが学習由来なのか検索由来なのかを分けないと、打つべき施策が決まらない。
サービスごとに切り分けの可否が違った
ただ、この切り分けが綺麗にできるかはサービスによって差があった。ここは限界も含めて記録しておく。
ChatGPTは、設定の高度なオプションに「ウェブ検索」のトグルがあって、これをオフにできた。デフォルトは検索オンで、質問内容によっては自動で検索が走る。だから診断のときは必ずオフにする。注意点として、設定でオフにしても、チャット画面のウェブボタン(地球儀アイコン)を押せば個別に検索できるので、そこは押さない。つまりオフにすれば学習知識だけで答える状態になる。念のため、回答に最新情報や引用の痕跡がないかを目視で確認しておくと確実だ。
Geminiは、チャット内の検索だけを明示的にオフにするトグルが、はっきり見当たらなかった。Google検索との統合が深くて、学習知識と検索結果の境界が曖昧。純粋に学習データだけの状態を作るのは難しいと判断した。
Perplexityは、そもそも検索が前提のサービスで、検索オフの概念がほぼない。学習の診断には向かないが、引用元URLを明示するので、検索インデックスと引用の診断には一番使いやすい。
検索オフで誤情報が出たら、エンティティ未確立
実際に、ある事業者の名称を検索オフでAIに聞いてみた。すると「知らない」ではなく、実在しない複数の拠点を挙げて、実際の主力とは違う事業分野を語ってきた。
これはエンティティが確立していないサインだと整理した。エンティティとは、AIの中で「他と区別できる一つの独立した実体」として認識されている状態のこと。法人や事業として実在していても、AIの中で確固たる実体として定着しているとは限らない。
なぜ誤情報が出るのか。AIは次に来る言葉の確率を計算していて、正しい答えの確率が突出していればそれを選ぶ。ところが突出した候補がなく、複数候補が似た確率でばらけると、その中からなんとなく一つが選ばれて、もっともらしい誤りになる。同じ名称の別の対象や、似た特徴の他社情報が混ざり込んでいた。AIの中でその名称の像が一つに定まっていない、ということだ。
「検索オンで正確ならいいのでは」を潰しておく
ここで検索オンにすれば公式サイトを見て正確に答えるのだから、わざわざ学習側を直さなくてもいいのでは、という意見も出てきそうだが、これは潰しておきたい。
カンニングペーパーで例えると分かりやすかった。検索オンは、AIにカンペ(公式サイト)を見せながら答えさせている状態。指名検索は「このカンペを見て答えて」だから、当然正確に書ける。でも一般検索の場合は「大量のカンペの束から条件に合うものを選んで」だから、その実体が選ばれるかは、カンペがあるかではなく、AIの頭に「この分野ならこの対象」という像が焼き付いているかで決まる。エンティティが弱いと、検索オンでも候補の山から選ばれない。
しかも検索オンでも学習データの誤りがノイズとして混ざることがある。実際に検索オンで試したとき、公式情報を引いているのに、拠点の紐付けが部分的に乱れていた。エンティティが強ければ、検索オンでもオフでも一貫して正確になるはず。
結局、エンティティ確立は検索オフのユーザー向けの施策ではなく、検索オン・オフ両方で正確に・選ばれやすく出るための土台だと整理できる。検索オフのテストは、その土台の弱さを測る試験紙にすぎない。試験紙が真っ赤なら、検索オンの一般検索という本番でもまず勝てていない、ということになる。
診断結果は4パターンに分かれる

検索オフ(学習)と検索オン(検索)の結果を組み合わせると4パターンになる。次にやることが変わるので、整理して残す。
検索オフで出ない・検索オンで出る。検索は通っているが学習に定着していない。学習されるための土台づくり、つまりエンティティ確立を強化。
検索オフで出る・検索オンでも出る。両方通っている強い状態。認識が正確かのチェックと維持。
検索オンでも出ない。検索インデックスから落ちている。検索系クローラーにクロールされているかの確認と、引用されやすいコンテンツ構造への改善。
検索オフで誤情報、という症状。他と混同されている。同名・類似と区別できるよう識別性を固める。
どれに当てはまるかは、検索オン/オフ、指名/一般を実際に叩かないと分からない。だから診断が先になる。
これはあくまで現時点での自分の仮説をふまえた内容で記載している。
まとめ
AI検索の現状把握は、ログ(前提条件層)だけでは半分で、AIに直接聞く(結果層)まで含めて成立する。その際、検索オン/オフで学習と検索を分け、指名/一般を分けて記録する。
そして、検索オンで正確に出ても安心しない。それは指名された場合の話で、新規客が来る一般検索では、エンティティの強さがないと選ばれない。検索オンで正確だから対策できている、と判断した瞬間に新規獲得の機会を見落としてしまうことになる。