BigQueryの権限がわからない。やりたいことから逆引きで必要なロールを選ぶ

この記事は誰向けか
GA4やSearch ConsoleのデータをBigQueryで触り始めた人、クライアントや取引先のBigQueryにアクセスさせてもらう立場の人、社内で誰かにBigQueryの権限を渡す立場になった人。この記事はそういう「権限まわりで一度はつまずいた、もしくはこれからつまずく」非エンジニア向けに書いています。
最初に公式ページを見た時は、何がなんだか全く分からずテンションが下がってしまいましたが備忘録も兼ねて、記事として残します。
BigQueryの権限は、公式サイトのように全部のロールを覚える必要はありません。やりたいことを決めて、そこから必要なロールを逆引きすれば、実務で迷うことはなくなります。この記事を読み終えるころには、自分のやりたいことに対して「どのロールを、どこに付ければいいか」を自分で判断できるようになります。
なぜ公式サイトだと迷子になるのか
公式サイトが分かりにくい理由はシンプルで、何十種類もあるロールをフラットに一覧で並べて、それぞれの権限がどのリソースに効くかを表にしているだけだからです。読んだ人が最初に思うのは「で、結局わたしはどれを設定すればいいの?」です。
そこでこの記事は、ロールの種類から入るのではなく、やりたいことから入って、必要なロールだけを拾えるようにします。覚えるロールは最小限で十分です。
BigQueryの権限を理解する基本構造
最初に、全体が見える基本構造を整理します。
IAMとは
BigQueryの権限設定をしていると、必ずIAMという言葉が出てきます。IAMはIdentity and Access Managementの略で、Google Cloud全体のアクセス管理の仕組みのことです。「誰が(Identity)」「何に(リソース)」「何をできるか(Access)」を管理するシステムで、BigQueryの権限設定はすべてこのIAMを通じて行います。
BigQueryに限らず、Google CloudのサービスはIAMで権限を一元管理しているので、他のサービスでも同じ考え方が使えます。
IAMは概念の名前でもあり、GCPのコンソール上の操作画面の名前でもあります。「IAMを設定する」と「ロールを付与する」は同じ意味で、GCPのコンソールにあるIAMのページでロールを誰かに割り当てる操作が、そのままIAMの設定にあたります。
・IAM=Google Cloudのアクセス管理の仕組み全体の名前(概念)
・IAMの設定=GCPのコンソールのIAMページでロールを誰かに割り当てる操作(実作業)
ロールと権限は別物
BigQueryの話をするとき、ロールと権限という2つの言葉が出てきます。この2つを混同すると途端に分からなくなるので、先に整理します。
権限とは、できることの最小単位のことです。「テーブルのデータを読む」「クエリを起こす」といった個別のアクションが、それぞれ1つの権限です。この権限を直接ユーザーに割り当てることはしません。
ロールとは、その権限を役割ごとにまとめた詰め合わせパックです。たとえば「データ閲覧者」というロールの中には、データを読む・エクスポートするなどの権限がまとめて入っています。実際にユーザーに割り当てるのはこのロールです。
BigQueryの権限設定は「どこに(階層)」かける「どのロールを(役割)」の掛け算で決まります。
ロールと権限の関係:GA4と比べると分かりやすい
GA4を触ったことがあれば、話は早いです。GA4には管理者・編集者・マーケティング担当者・アナリスト・閲覧者という標準の役割があって、そこから1つを選んで人に割り当てます。BigQueryもまったく同じで、用途別に用意された役割(ロール)から選んで割り当てます。どの役割も、中身は複数の権限がまとまった塊だ、という点もGA4とBigQueryで共通です。
【GA4】権限付与の画面
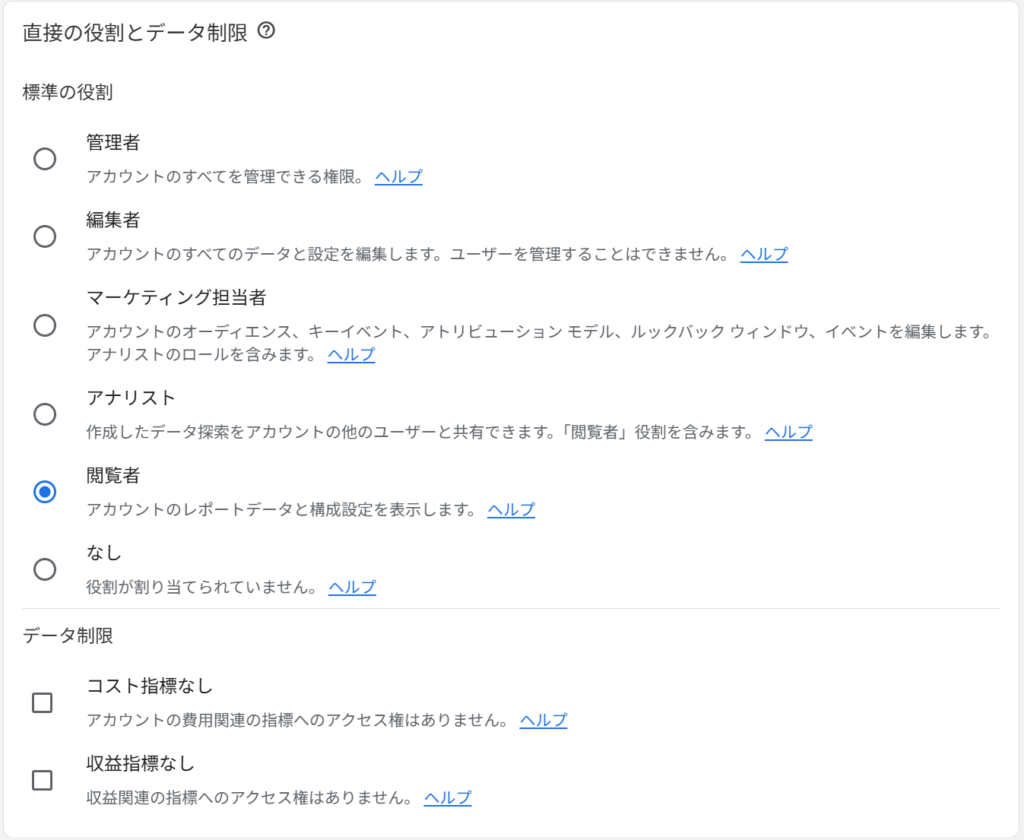
違いは2つあります。1つは、BigQueryのほうが役割が細かくて数が多いこと。もう1つが重要で、GA4にはない「ジョブユーザー」という役割がBigQueryには独立して存在することです。
図を見てください。左がGA4、右がBigQueryの役割を並べたものです。管理者や閲覧者は左右で対応していますが、BigQuery側だけ点線の下に「ジョブユーザー」がぶら下がっています。GA4は閲覧者を選べばレポートが見られて、それで完結します。ところがBigQueryは、データを見る役割とは別に「クエリを実行する役割」が切り離されている。この分離が、初心者が最初につまずく原因になります。

どの階層に付けるか
もう1つ、置き場所の話をします。BigQueryのリソースは、外側から順にプロジェクト、データセット、テーブルという入れ子になっています。組織やフォルダもありますが、初心者はこの3階層だけ意識すれば十分です。
そして、ロールによって付けられる階層が違います。ジョブユーザーはプロジェクトにしか付けられません。一方、閲覧者・編集者・オーナーはデータセット単位で付けられます。
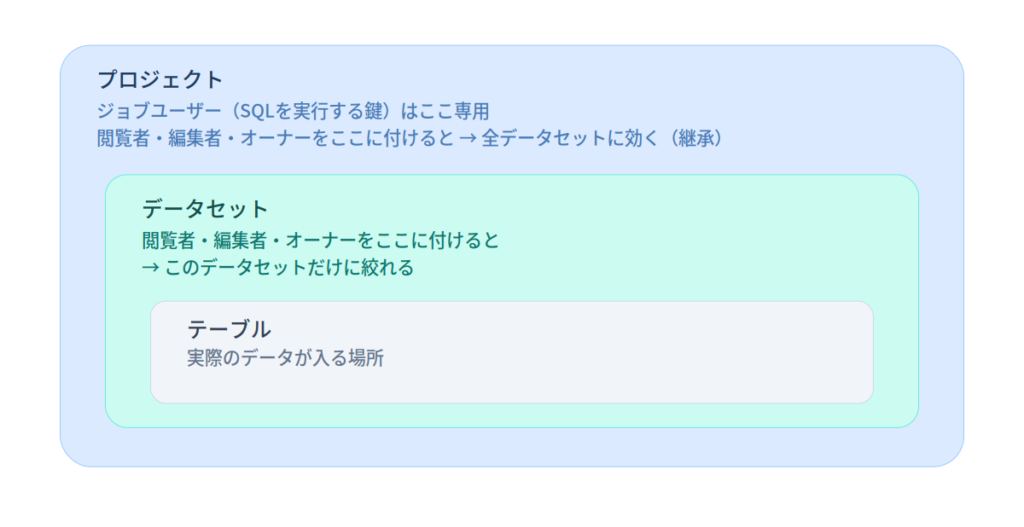
図で確認してください。ジョブユーザーはプロジェクト専用で、データセットには付けられません。閲覧者・編集者・オーナーはプロジェクトにもデータセットにも付けられますが、どちらに付けるかで効く範囲が変わります。
プロジェクトに付けると、その中の全データセットに効きます。これを継承といいます。広く権限を与えたいときはプロジェクトに付けるのが手っ取り早いですが、「この案件のデータだけ見せたい」という場面では使いにくい。
データセットに付けると、そのデータセットだけに絞れます。見せたいデータセットにだけ閲覧者を渡せば、他の案件のデータは見えません。実務でクライアントや外部パートナーに権限を渡すときは、この絞り込みが重要になります。
なお、権限を設定する場所はロールによって違います。同じGoogleのUI内でも、操作する画面が分かれています。
プロジェクトにロールを付ける場合は、GCPのコンソールからIAMのページで設定します。
下記で追加したいメールアドレスを追加
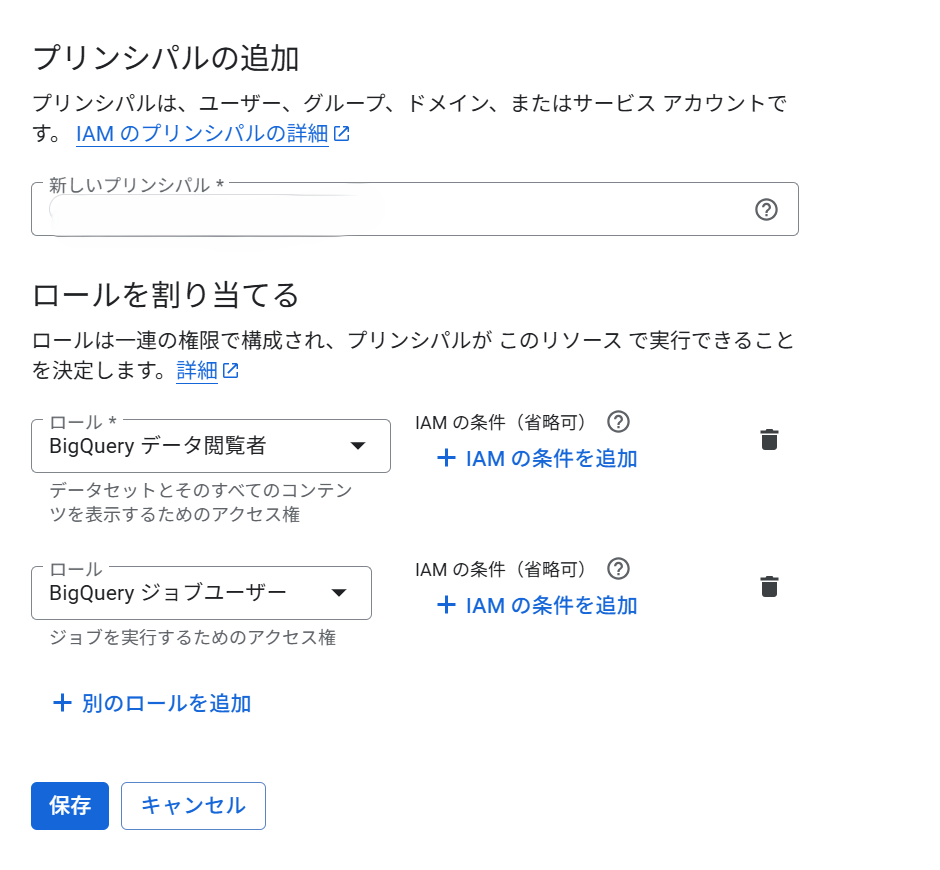
データセットにロールを付ける場合は、BigQueryのコンソールからデータセットを開いて「共有」→「権限を追加」で設定します。
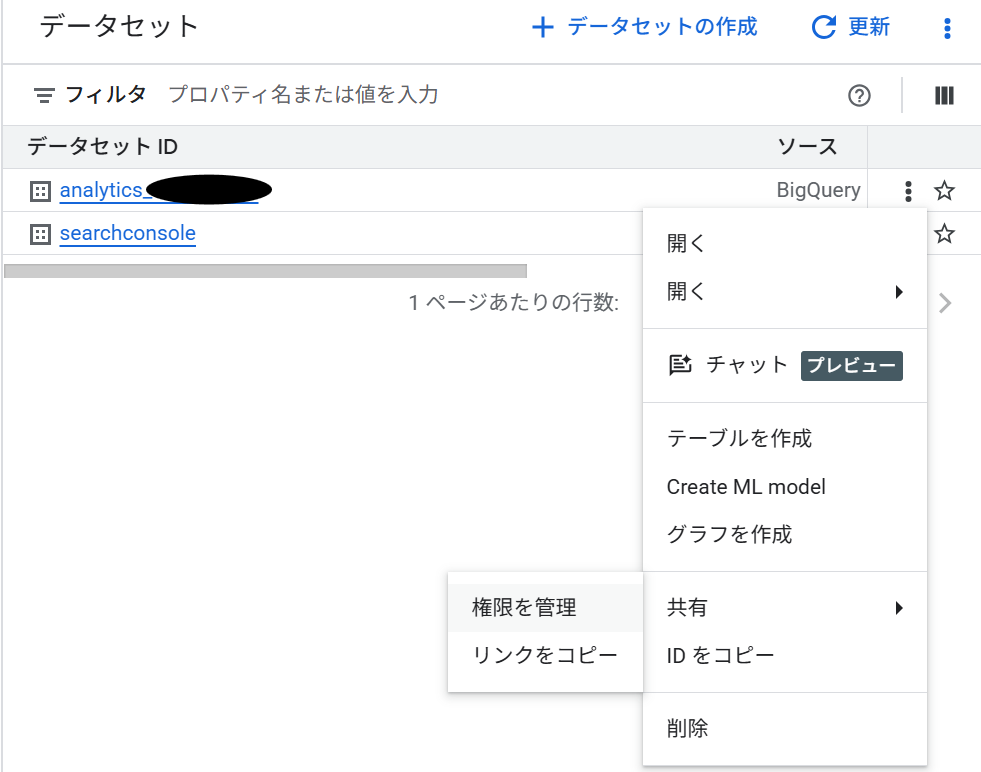
「データセット単位で絞れる」という話をしていても、BigQueryの画面から別途設定する必要があることを知らないと、設定した気になってプロジェクトのIAMにしか付けていない、ということが起きます。
やりたいことから引く:シーン別早見表
この表で自分のやりたいことの行を探せば、必要なロールが1つか2つに絞れます。
| やりたいこと | 必要なロール |
|---|---|
| データをただ見る(自分でSQLは書かない) | データ閲覧者 |
| 自分でSQLを書いて分析する | データ閲覧者 + ジョブユーザー |
| テーブルを作る・データを書き換える | データ編集者 + ジョブユーザー |
| データセットを管理し、人に権限を配る | データオーナー |
| プロジェクト全体を管理する | 管理者 |
「自分でSQLを書いて分析する」と「テーブルを作る・書き換える」で、どちらもジョブユーザーが入っているのに気づくと思います。これは後で説明する落とし穴に直結する、いちばん大事なポイントです。
次に、実務でよくある「他社とのやり取り」のパターンです。
| 実務シーン | もらう/渡す最小セット |
|---|---|
| 取引先のBigQueryを見せてもらう(自分が分析する) | 相手のプロジェクトにジョブユーザー + 見たいデータセットにデータ閲覧者 |
| 自分のBigQueryに外部の人を招く(見せるだけ) | プロジェクトにジョブユーザー + 見せたいデータセットだけにデータ閲覧者 |
ここで言いたいのは、念のため管理者を渡す・もらう、と考えがちですが、実際はこの組み合わせで足りるということです。データセット単位で絞れるので、他の案件のデータは見えません。最小権限で組めると、渡す側も安心しますし、頼む側の信頼にもつながります。
よく使うロールだけ詳しく
全部は覚えなくていいので、実務で使う6つだけ、できること・できないこと・いつ使うかをまとめます。
管理者
プロジェクト内のすべてのリソースを管理できます。他のユーザーが実行中のジョブをキャンセルすることもできる、最も強い役割です。便利な反面、配りすぎると事故のもとになるので、本当に管理を任せる相手にだけ、プロジェクト単位で渡します。
データオーナー
データセットとその中身に対するすべての権限を持ち、さらにアクセス制御(誰に権限を渡すか)やデータセットの削除までできます。データセットの責任者に渡す役割です。プロジェクト全体の管理まではできません。
データ編集者
テーブルの作成・更新・削除と、データの読み書きができます。分析の中間テーブルやビューを作りたい人向けです。ただし、人に権限を配ることやデータセットの削除はできません。
データ閲覧者
データの参照とエクスポートができます。読むだけの人はこれで十分です。データの書き込みはできませんし、これ単体ではクエリを実行できない点に注意してください(理由は次章)。
ジョブユーザー
クエリやジョブを実行する役割です。ただしデータそのものを見る権限は持っていません。SQLを動かすための役割で、プロジェクト単位でしか付けられません。
初心者が必ずハマる落とし穴
ここが私自身がつまずいた箇所でもあるので要注意。
閲覧者だけ付けても、クエリが動かない
早見表で「自分でSQLを書いて分析する」に、閲覧者とジョブユーザーの両方が必要だったのを覚えていますか。これが最大の落とし穴です。

データ閲覧者には、テーブルのデータを読む権限はあるのですが、ジョブ(クエリ)を実行する権限が含まれていません。一方でジョブユーザーは、クエリを実行する権限を持っています。だから「データを読む鍵(閲覧者)」と「SQLを実行する鍵(ジョブユーザー)」の2本がそろって初めて、クエリが走ります。
GA4だと「閲覧者にしたのにレポートが見られない」なんてことは起きません。BigQueryは役割が機能ごとに分かれているせいで、片方だけだと動かない。ここをGA4の感覚で来ると、一度引っかかります。
なお、図の中では分かりやすさを優先して「SQLを実行する」と書いていますが、これは正式にはジョブ実行権限、ロールの名前でいうとジョブユーザーです。
「BigQuery ユーザー 」と「ジョブユーザー」を混同する
これは私自身が実務で混乱した所です。BigQueryには「ジョブユーザー」とは別に「BigQuery ユーザー 」という、名前のよく似た役割があります。
ジョブユーザーは、クエリを起こすだけです。データも読めませんし、データセットも作れません。
BigQuery ユーザーは、それに加えて自分でデータセットを作れて、自分が作ったデータセットの中なら読み書きできます。ただし、他人が作った既存のデータセットは読めません。たとえばGA4のエクスポート先のデータセットを読みたければ、ユーザーを持っていても別途データ閲覧者が必要になります。
名前が似ているので「ユーザーを付けたのに既存データが読めない」と混乱しがちです。役割が違う、という前提で見てください。
管理者を安易に配ってしまう
「とりあえず全部できる管理者を渡しておけば困らない」と考えがちですが、これは最小権限の原則に反します。読むだけの人に管理者を渡すと、その人は他人のジョブを止めることもデータを消すこともできてしまう。やりたいことに必要な最小限の役割を選ぶのが、安全で、トラブルも起きにくい組み方です。
プロジェクトに付けた権限は、中のデータセットにも引き継がれる
外側のプロジェクトにロールを付けると、その中のデータセットにも効きます。「データセット単位で絞ったつもりが、プロジェクトに付けた権限のせいで全部見えていた」ということが起こり得ます。絞りたいときは、プロジェクトには最小限だけ付けて、見せたいデータセットにだけ追加で付ける、という設計にします。
保存版チートシート
最後に、1枚で見返せる早見表を置いておきます。ブックマークして、迷ったときに戻ってきてください。
| ロール | ひとことで | できること | できないこと | 付ける場所 |
|---|---|---|---|---|
| 管理者 | 最上位、全部できる | プロジェクト内の全操作・他人のジョブ管理 | ほぼ制限なし | プロジェクト |
| データオーナー | そのデータセットの主 | 読み書き+権限付与+データセット削除 | プロジェクト全体の管理 | データセット |
| データ編集者 | 読み書き担当 | テーブル作成・編集・データ読み書き | 権限付与、データセット削除 | データセット |
| データ閲覧者 | 見るだけ | データ参照・エクスポート | 書き込み、単体ではクエリ実行 | データセット |
| ジョブユーザー | クエリを動かす鍵 | クエリ・ジョブの実行 | データそのものは見られない | プロジェクト |
迷ったら、この3行だけ覚えておけば足ります。
とにかく分析したいなら、ジョブユーザー(プロジェクト)とデータ閲覧者(データセット)。
編集もしたいなら、上の「閲覧者」を「編集者」に変えるだけ。
権限を配る立場になったら、データオーナー。それ以上が必要なら管理者。
まとめ
BigQueryの権限は、全ロールを覚えるものではなく、やりたいことから逆引きするものです。データを見る鍵(閲覧者・編集者)と、SQLを実行する鍵(ジョブユーザー)が別々で、組み合わせて使う。これさえ押さえておけば、自分の作業にも、人への権限の渡し方にも、もう迷いません。